
The quality of the scans used for OCR is one of the two factors deciding the quality of the output of OCR4all (the other being font training). Since I have mostly ocr’ed incunables and early 16th-century prints, this has been a major concern. ‘My’ books are often heavily discolored and hardly ever equally illuminated, since pages towards the spine often curve away from the camera and thus reflect light differently from the rest of the page. This usually does not impact the legibility of the original scans, but bitonal conversions often turn the beginning of the line into a black blob that even the ingenuity of OCR4all cannot make sense of. I have tried to improve the legibility of the scan by heightening the contrast, changing the histogram curve with Adobe Lightroom, setting the scanning parameter in OCR4all to greyscale instead of bitonal (not a success in my few attempts), creating bitonal output with Scantailor (only a success if the scan is rather uniform), etc. This blog is about the circuitous route to create optimized input for OCR4all.
1. Choice of software
My usual ocr-workflow includes a number of free as well as commercial programs (all under MS Windows). For file manipulations (rename etc.) I use TotalCommander (commercial, but with a neglegible cost per license), image preparation happens with ScanTailor (free, open source), image conversions with IrfanView (free), of course OCR4all (free, open source), and postprocessing with EML-txt2txt (free). This leaves quality improvements of the scans, if necessary. In my experience, OCR4all in the standard settings does not cope well with color scans that are too unequally illuminated. So far I have used Adobe Lightroom, which has an excellent curve tool for changing the lighting of a page and a superintuitive batch mode. Lately I have felt that I should try to replace it with another program - GIMP being the obvious candidate. The reason is purely economic: I own one licence of Lightroom which is installed on my home laptop. I work, however, on several PC’s, so I need software that can be installed anywhere (legally).
2. What happened so far
The book in question is Raffaele Maffei’s Commentaria Urbana, one of the standard encyclopedias of the sixteenth century. Since the book with nearly 1000 pages is substantial, it has been little studied; we know next to nothing about Maffei’s Latin, even though it must have influenced countless readers of his Commentaria. I have chosen one of the later editions, Basileae 1544, in a copy owned by the Bayerische Staatsbibliothek, Munich (BSB 1563368938bsb10150226). OCR4all produces nearly error-free output already with the default antiqua model (!), aside from the innermost one or two centimeters of every line. The print has the usual marginal notabilia which I have cut with ScanTailor. ScanTailor can output b/w images, this however, due to the uneven illumination, does not normally produce a usable result, since either the inner margins default to black, or the rest becomes dangerously white. (If you are getting impatient while reading this, you can now jump to the end). Therefore I output color images. Just for the purposes of this post, I threw the ScanTailor export test page into OCR4all:

Color image - output of ScanTailor
Unfortunately, OCR4all transforms this into a bitonal scan where the left margin is missing:

Color image - bitonal conversion by *OCR4all*
Consequently, the ocr is excellent, as expected, aside from the fact that the first one or two letters of every line are left off:

Ground Truth of the first lines with the first letters missing
3. GIMP curve tool
I turn to GIMP (2.10.12-3), which offers Batch Manipulation with previously defined presets. My plan is (a) to define the necessary improvements to the contrast, and (b) to apply them to all pages. First I try the easy way out by googling “Gimp bw conversion” and similar; the suggestion I turn up is Image > Mode > Indexed and use the black and white palette. With normal Floyd-Steinberg dithering this turns my page into a hopeless mess of speckles. With “reduced color bleeding” the page has strangely dotted characters, but is perfectly legible:

Bitonal conversion with *GIMP* - character outlines are dotted
OCR4all, however, cannot segment the lines - end of story. GIMP’s ‘Equalize’-command, another suggestion from Google, returns a dark illegible result (as predicted by many users).
Since there seems no easy way out, I tackle the real problem, the uneven coloring of the page. For this I use the Curve-tool:
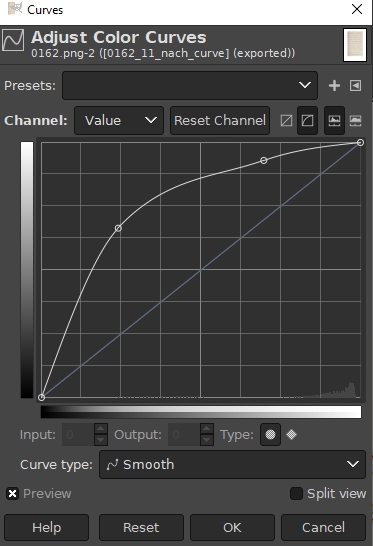
GIMP's curve tool
which lightens the left margin of the test page without degrading the rest too much:

Inner margin of the page now lightened
4. GIMP threshold tool
By chance I detect GIMP’s Threshold tool which produces a clean b/w picture without a speckle in sight. This is a beautifully programmed piece of GIMP:
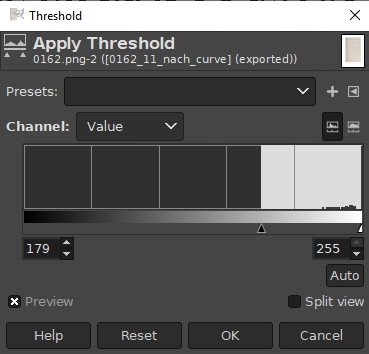
GIMP's Threshold tool
After a bit of experimenting with the slider I settle on a threshold of 179. The letters on the left still have thicker strokes, but the rest retains enough information for ocr:

Bitonal conversion with *GIMP*'s Threshold tool
The result of a test run with OCR4all is excellent (though strangely the ‘a’ in the first ‘patriae’ has not been recognized):

OCR after application of GIMP's curve and threshold
5. Batch processing failure
Now these two GIMP tools need to be applied to the 995 pages of the Commentaria. First I turn to Batch Manipulation in GIMP. Turns out it can be used only with a very limited set of commands, curve and threshold not being among these. I should have remembered that from another attempt a couple of years ago. I know that in theory GIMP can also be started from the commandline, so a script might do the trick. Since I have never used the scripting language (Script-Fu) of GIMP, I turn to Google and find at least two promising scripts for older versions of GIMP. There is also a newly introduced command ‘with-files’ that takes care of the batch application of scripts (carefully explained in the script ‘script-fu-util.scm’ which is standard with version 2.10). I spend a couple of hours on a Sunday morning trying to get any of the example scripts to work. Mostly, GIMP cheerfully assures me that the batch commands have been successfully executed. It’s just that nothing happens to my scans. After thoughts of lunch begin to intrude on my futile activity, I conclude that I am doing something wrong which is so elementary that nobody has thought of mentioning it.
6. Starting b/w: a Google-scan
After lunch the obvious solution presents itself: I will look for a Google-scan of the same book (since BSB and Google cooperate), which - unlike the BSB-scan - is already bitonal:

Bitonal Google-scan
Google has done an excellent conversion job, the scans are perfectly and evenly legible, even though they are not nearly as beautiful as the color scans of the BSB. To avoid any losses, I have ScanTailor output a grey image:

Output by ScanTailor - grey conversion from bitonal original
This is not a good idea; OCR4all cannot cope with the grey-scale image:

OCR4all conversion of grey ScanTailor output
And the ocr result is not good:

'patriae' is not read correctly, 'gloria' becomes 'gioria', first letter in the second line is missing, same for some letters at the beginning of the third line, etc.
Next step: I convert the ScanTailor-grey to a bitonal image with Irfan. The ocr is better, but not nearly as good as my first results with GIMP. Lot of missing characters (most of which could be trained). The last line on the page is not read at all (a phenomenon I have never encountered before).
Next variant: bitonal output by ScanTailor of bitonal Google scan. The thickness of the lines does not change with the slider in ScanTailor; the characters of the first ‘patriae’ are hardly distinguishable. I dont even try to ocr this one.
7. Back to the color BSB-scan and ScanTailor
Next idea is one I had discarded earlier: Producing a bitonal output of the color BSB-scan with ScanTailor and trying to find a sweet spot where the inner margin of the page becomes readable by OCR4all, while the rest retains enough information so as to be still readable. I settle on a measure of -40 and mild despeckling:
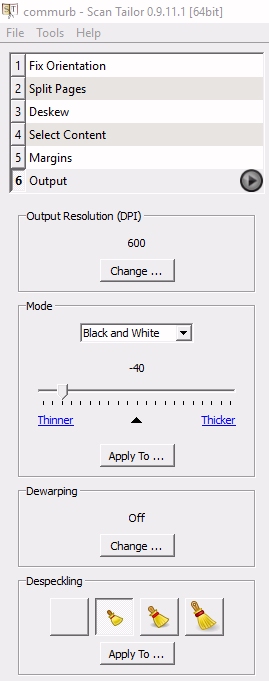
ScanTailor output settings
The output is not especially nice:

ScanTailor bitonal conversion of color scan
but, the graphics algorithm of OCR4all seems content with the input (no perceptible further changes/degradation) and the ocr is - again - excellent (note that ‘patriae’ is read correctly!):

ocr of ScanTailor bitonal conversion
This is the result with the standard ‘historical antiqua’ font (not training)! So maybe this is it. Easy solution to a hard problem. Now I have to try it with the whole book. I will update this post if necessary.
Software and internet sites mentioned in this blog post: TotalCommander, ScanTailor, IrfanView, OCR4all, EML-txt2txt, GIMP, MS Windows, Adobe Lightroom, Google, Bayerische Staatsbibliothek.